Try It Yourself
Enter values below, then hit Predict to see what the model says.
Raw Dataset (original data)
| Rk | Player | Age | Team | Pos | G | GS | MP | FG | FGA | FG% | 3P | 3PA | 3P% | 2P | 2PA | 2P% | eFG% | FT | FTA | FT% | ORB | DRB | TRB | AST | STL | BLK | TOV | PF | PTS | Awards | Player-additional |
|---|
Cleaned Dataset (the version we feed to the model)
| PTS | AST | MP | AllStar |
|---|
The Code (how we built this model)
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
df = pd.read_csv('nba_allstar_original.csv', skiprows=1)
df['AllStar'] = df['Awards'].str.contains('AS', na=False).astype(int)
df = df[['PTS', 'AST', 'MP', 'AllStar']]
df = df.dropna()
X = df.drop('AllStar', axis=1)
y = df['AllStar']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = DecisionTreeClassifier(max_depth=3, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(accuracy_score(y_test, y_pred))
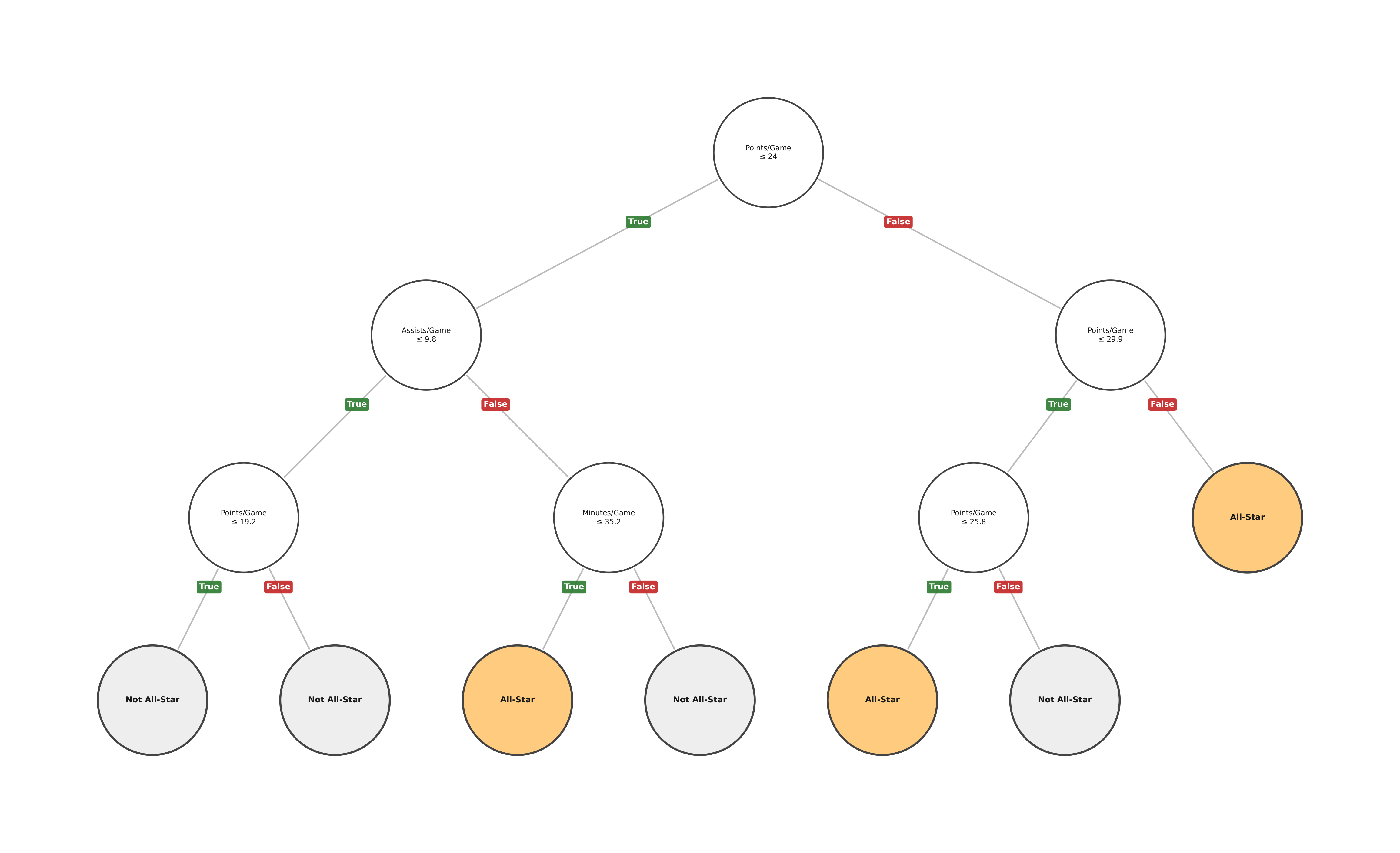
Under the Hood (how the model thinks)
This is the actual decision tree the model learned. Starting from the top, each diamond asks a yes/no question — follow True left and False right until you reach a coloured leaf, which is the final prediction.